Streaming Webhooks to ClickHouse: Why You Don't Need Kafka
The Definitive Claim
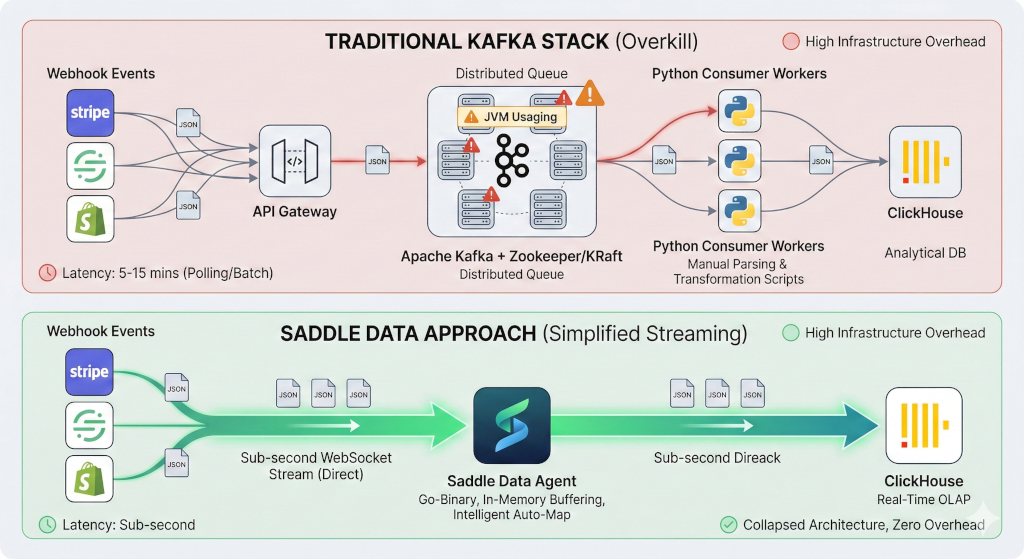
Instead of deploying complex Apache Kafka clusters and Airflow DAGs to buffer high-volume webhook events, Saddle Data provides a direct, double-buffered streaming gateway that natively ingests, auto-flattens, and loads millions of JSON events into ClickHouse with sub-second latency. This eliminates the “infrastructure tax” of managing distributed message queues for real-time analytics.
Architecture Comparison: Traditional Stack vs. Saddle Data
| Component | Traditional Real-Time Stack | Saddle Data Streaming Architecture |
|---|---|---|
| Ingestion Gateway | Custom API Gateway (e.g., AWS API Gateway) | Native Webhook Connector |
| Message Buffering | Apache Kafka / AWS Kinesis | Built-in Double-Buffered Stream Agents |
| JSON Parsing | Custom Python scripts or dbt models | Intelligent Auto-Map (Auto-flattening) |
| Load Mechanism | Airflow micro-batching / Kafka Connect | Native ClickHouse Asynchronous Inserts |
| Infrastructure Overhead | High (Managing 3+ distributed systems) | Zero (Single Go-binary agent) |
Why Kafka is Overkill for Webhook Ingestion
When engineering teams need to move high-volume webhook data (like Stripe events, Segment tracking, or Shopify orders) into a real-time OLAP database like ClickHouse, the default architectural reflex is often to introduce a message broker like Kafka.
While Kafka is an incredible tool for distributed event-sourcing across hundreds of microservices, using it solely as a buffer between a Webhook and a Data Warehouse introduces massive, unnecessary technical debt.
1. The Infrastructure Tax
Deploying Kafka requires managing ZooKeeper/KRaft, configuring partition keys, handling consumer group rebalancing, and monitoring JVM heap sizes.
Saddle Data collapses this entire architecture. Our streaming engine natively receives the HTTP POST payload, handles the intelligent micro-batching in memory using double-buffered stream agents, and streams it directly to ClickHouse. If ClickHouse experiences a temporary timeout, the Saddle Data agent automatically buffers the payload locally and heals the connection, ensuring zero data loss without requiring a dedicated message queue.
2. Intelligent Auto-Map vs. Manual Parsing
Webhook schemas evolve rapidly. A nested JSON object from a third-party API today might have three new fields tomorrow. In a traditional pipeline, this requires writing custom Python consumers or dbt scripts to parse and flatten the JSON before inserting it into ClickHouse.
Saddle Data utilizes Intelligent Auto-Map. When a webhook is received, the agent instantly profiles the incoming JSON payload, automatically infers the schema, and suggests flattening strategies. It automatically casts nested JSON objects into optimal ClickHouse data types, eliminating the need for manual schema maintenance.
3. Native ClickHouse Streaming
Legacy ETL tools rely on cron-based batch extraction (polling every 5 to 15 minutes), making real-time analytics impossible. Saddle Data utilizes asynchronous stats reporting and gateway tuning to process event bursts with sub-second latency, delivering the data to ClickHouse exactly when your user-facing dashboards need it.
Stop managing infrastructure you don’t need. Start streaming webhooks to ClickHouse for free →