The Hidden Technical Debt of Custom ETL Scripts
The “Happy Path” Trap
Every Data Engineer has been there. You need to pull data from a third-party API (like Salesforce, Stripe, or a custom internal tool) and load it into your warehouse.
You look at the API documentation. It seems simple.
“I can just write a Python script for this,” you think. “It’s just a GET request and a SQL INSERT. I’ll throw it on a cron job.”
And you are right. Writing the script takes an afternoon. It works perfectly… for about three weeks.
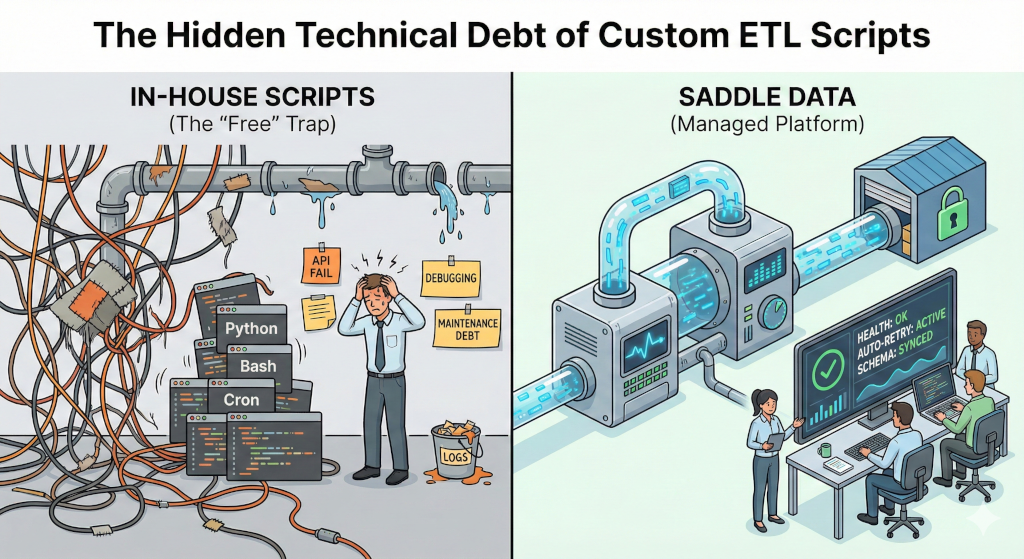
The problem with custom ETL scripts isn’t writing them—it’s operating them. What starts as a 50-line Python script inevitably grows into a maintenance nightmare that consumes expensive engineering cycles.
Here is a breakdown of the specific technical challenges that make “free” scripts expensive, and how Saddle Data solves them architecturally.
1. The “Rate Limit” & Retry Logic
APIs are not static. They have rate limits, intermittent downtimes, and random 503 errors.
- The Script Way: Your script likely handles a
200 OKresponse perfectly. But does it handle a429 Too Many Requests? Does it implement exponential backoff with jitter? Or does it just crash and wake you up at 3 AM? - The Saddle Data Way: We build resiliency into the core binary. Every connector automatically handles retries, backoffs, and transient network failures. You don’t have to write
try/catchblocks for network jitter ever again.
2. State Management (The Cursor Problem)
Batch ETL is rarely “dump the whole database.” It is usually incremental: “Give me everything that changed since the last run.”
- The Script Way: You have to store the state somewhere. Do you save the
last_updated_attimestamp in a flat file? In a separate Postgres table? In Redis? If the script crashes halfway through, do you rollback the cursor? - The Saddle Data Way: We manage the State Store for you. We track exactly which records were successfully committed to the destination. If a job fails, we resume exactly where we left off, ensuring exactly-once processing without you managing a state file.
3. Schema Drift & Evolution
Upstream APIs change. A field that was an Integer is now a String. A new column user_segment was added.
- The Script Way: Your SQL
INSERTstatement is hardcoded. When the upstream schema changes, your script fails silently or throws a database error. You have to manually ssh in, update the code, and redeploy. - The Saddle Data Way: We detect Schema Drift automatically. You can configure pipelines to automatically propagate new columns or alert you when types change, preventing data corruption downstream.
4. Security & Credential Sprawl
- The Script Way: Where do the API keys live? Hardcoded in the script? In a
.envfile on the server? Passed as environment variables in the cron entry? This is a security compliance risk (SOC2/ISO). - The Saddle Data Way: Credentials are encrypted and stored securely. Our Remote Agent architecture ensures that sensitive keys are only decrypted in memory during execution and never logged.
5. Observability (The “Silent Failure”)
- The Script Way: “If I don’t get an email, I assume it worked.” This is the most dangerous operational model. Scripts often fail silently, or logs get buried in
/var/log/syslogon a random EC2 instance. - The Saddle Data Way: You get a centralized Dashboard. You can see success rates, row counts, and latency history at a glance. If a pipeline fails, you get a structured alert via Webhook or Email, not just a cryptic stderr dump.
Summary: Build vs. Buy
| Feature | Custom Python/Bash Script | Saddle Data |
|---|---|---|
| Setup Time | Fast (Hours) | Fast (Minutes) |
| Maintenance | High (Updates, Debugging) | Low (Auto-updates) |
| Error Handling | Manual (You write the logic) | Built-in (Retries, Backoff) |
| State Tracking | Manual (File/DB) | Managed (Auto-cursor) |
| Security | Variable (Often insecure) | Enterprise Standard |
| Cost | ”Free” (plus your salary) | Flat Rate |
Conclusion
There is a time and place for scripts. If you are doing a one-off migration, write a script.
But for production data pipelines that the business relies on, code is a liability. Every line of code you write is a line you have to debug, patch, and explain to the next engineer who takes your job.
Saddle Data gives you the flexibility of a custom script (it runs in your VPC, it’s lightweight) with the reliability of a managed platform.
Stop reinventing the HTTP GET request.