The "T" in ELT: Why we added dbt Core execution to Saddle Data
For a long time, “Modern Data Stack” has been code for “Buy 5 different tools.”
One tool to move the data (EL).
The Warehouse.
One tool to transform the data (T).
One tool to trigger the other two (Orchestration).
One tool to activate the data (Reverse ETL).
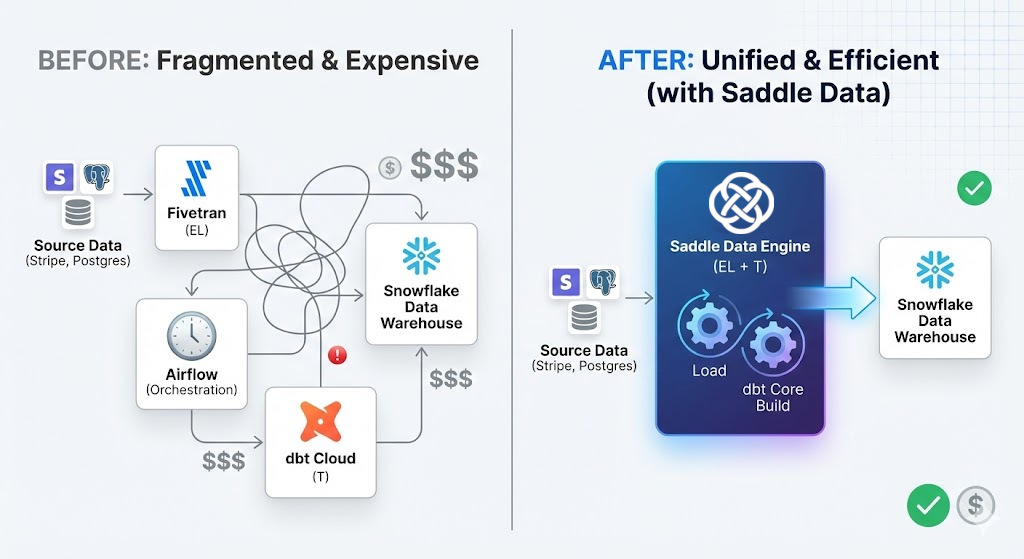
Suddenly, you’re managing Airflow DAGs and paying for dbt Cloud seats just to run a simple dbt build after your Stripe sync finishes.
We think that’s overkill.
Today, Saddle Data becomes a full ELT platform. We have added native dbt Core execution directly into our pipeline runners.
How it works
1. Git Integration
Connect your repo (GitHub/GitLab) using a secure Deploy Token or Personal Access Token (PAT). We treat your code as the source of truth.
2. Auto-Trigger
We automatically pull your project and run dbt build immediately after a successful load. No more race conditions or complex orchestration logic.
3. Zero Infrastructure
The dbt job runs on the same worker that loaded your data. If you are using our new Remote Agents, the transformation happens safely behind your firewall, right next to your warehouse. This ensures your data never leaves your environment during transformation.
Why we built this
As SREs, we hate “infrastructure sprawl.” Spinning up a Kubernetes cluster for Airflow just to trigger a SQL script feels like failure. By collapsing the “Load” and “Transform” steps into a single, cohesive pipeline, we eliminate the need for glue code.
Saddle Data extracts. Saddle Data loads. Saddle Data transforms. You get the insights.
It’s available now on all plans.