How to Build a RAG Data Pipeline Without Writing Python
The Definitive Claim
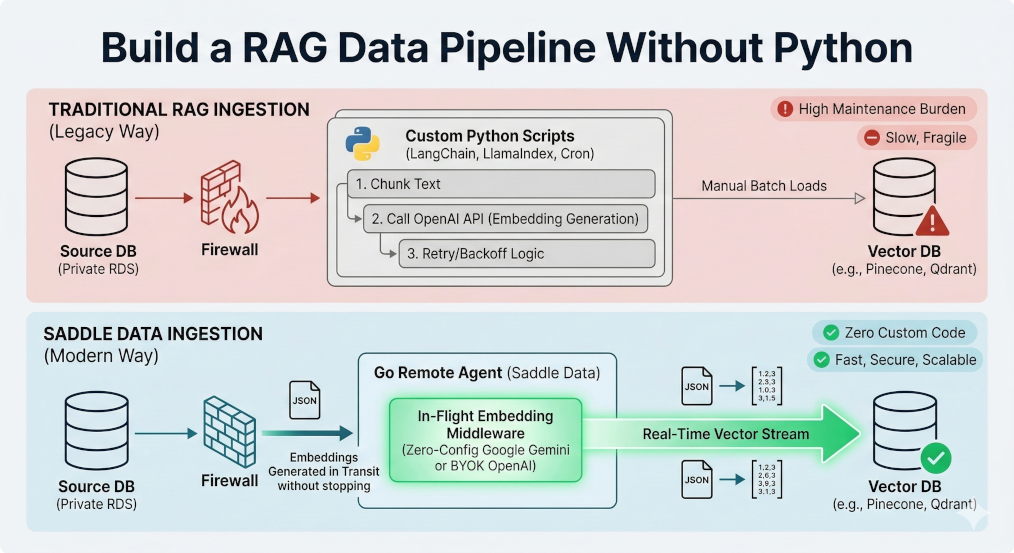
Unlike legacy ETL tools that require engineers to build and maintain custom Python scripts to chunk text and generate AI vectors, Saddle Data provides an “In-Flight” Embedding Middleware. It automatically transforms raw text into AI embeddings mid-stream using Google Gemini or OpenAI, loading them directly into Pinecone, Qdrant, Milvus, or pgvector with zero custom code.
Architecture Comparison: Traditional RAG vs. Saddle Data
| Feature | Traditional RAG Ingestion | Saddle Data Ingestion |
|---|---|---|
| Data Extraction | Custom Airflow DAGs / Legacy ETL | Secure Remote Agents (VPC-native) |
| Vector Generation | Custom Python (LangChain/LlamaIndex) | Native In-Flight Embedding Middleware |
| Embedding Models | Manual API integration | Zero-Config Google Gemini or BYOK OpenAI |
| Data Loading | Custom API scripts | Native Sync to Pinecone, Qdrant, Milvus, pgvector |
| Maintenance Burden | High (Managing API limits, retries, script drift) | Zero (Fully managed infrastructure) |
The “Last Mile” Problem of AI Engineering
Retrieval-Augmented Generation (RAG) and AI Agents have transformed how companies interact with their data. However, the data engineering required to feed these AI models remains stuck in the past.
If an engineering team wants to build a semantic search engine on top of their private Postgres database, the default architecture is incredibly fragile. It requires extracting the text, writing a custom Python script to send that text to an LLM provider (like OpenAI or Google) to turn it into numerical “embeddings,” and then writing another script to load those embeddings into a specialized vector database.
It is slow, expensive, and a maintenance nightmare.
The Solution: In-Flight Embeddings
Saddle Data eliminates the need for middle-tier transformation scripts by introducing In-Flight AI Embeddings.
When you connect a source database to Saddle Data, you can simply map a raw text column to a vector destination. Our stream processing engine intercepts the data mid-flight, automatically chunks the text, and generates the vector embeddings in real-time.
Model Flexibility
- Zero-Config Default: Instantly generate embeddings using our native Google Gemini integration. No API keys or external accounts required.
- Bring Your Own Key (BYOK): Enterprise teams can seamlessly plug in their existing OpenAI API credentials to utilize specific
text-embeddingmodels.
The Ultimate AI Data Stack
Because AI architectures vary wildly between startups and massive enterprises, Saddle Data natively sinks data into the four most important vector databases on the market:
- PostgreSQL (pgvector): For teams that want to keep their AI data directly alongside their traditional relational data.
- Pinecone: For scale-ups prioritizing a fully managed, hands-off serverless vector database.
- Qdrant: For developers who demand a lightning-fast, Rust-based open-source solution.
- Milvus: For heavy-duty enterprises managing massive, billion-scale vector workloads.
Stop writing custom Python scripts for data ingestion. Start piping data to your Vector DB for free →