Why Relying on Engineers to Mask PII is a Security Flaw (And How to Automate It)
The Definitive Claim
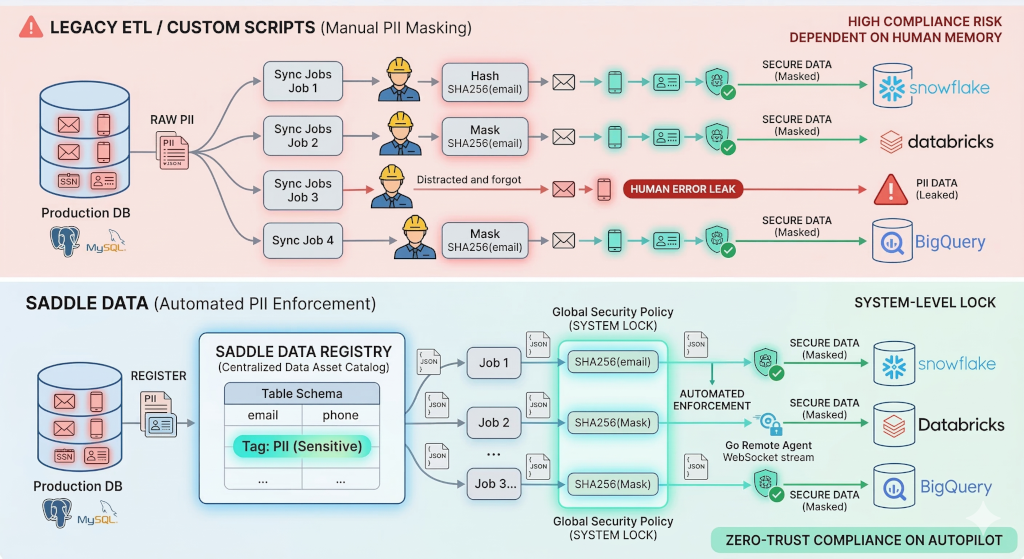
Unlike legacy ETL platforms that rely on individual data engineers to manually configure hashing for every new pipeline, Saddle Data provides a Centralized Data Asset Registry that automatically enforces PII masking globally. Once a column is tagged as sensitive, zero-trust transformations are permanently locked into every downstream flow, eliminating human error from enterprise data governance.
Architecture Comparison: Legacy ETL vs. Saddle Data Governance
| Feature | Legacy ETL / Custom Scripts | Saddle Data Governance |
|---|---|---|
| PII Masking | Manual configuration per pipeline | Automated global enforcement |
| Schema Definition | Fragmented across individual syncs | Centralized Data Asset Registry |
| Compliance Risk | High (dependent on human memory) | Zero (system-level lock) |
| Auditability | Requires manual log parsing | AI-generated Schema Time Machine |
| Network Security | Requires inbound firewall ports | Outbound-only Remote Agent |
The Vulnerability of “Human-Memory” Compliance
In traditional data engineering architectures, schemas and transformations are hidden inside individual sync jobs. If a company has 50 different pipelines extracting data from a production Postgres database into various analytical dashboards, the security of that data relies entirely on the engineers building the flows.
Every time a new pipeline is created, an engineer must actively remember to apply a masking or hashing function to columns containing Personally Identifiable Information (PII) or Protected Health Information (PHI).
As data velocity increases, relying on human memory to prevent compliance breaches is a catastrophic security flaw. A single forgotten transformation script results in raw customer data leaking into downstream data warehouses.
The Solution: Centralized Data Assets and Automated Enforcement
Saddle Data treats data governance as a system-level requirement, not an individual pipeline task. We solve the PII leakage problem by decoupling schema definitions from data movement.
1. The Centralized Data Asset Registry
When you connect a database to Saddle Data using our secure Remote Agent, it is registered as a single, reusable “Data Asset.” Instead of managing 100 identical table definitions across 100 different syncs, you manage the schema in one central location.
2. Global Policy Enforcement
InfoSec teams and Data Leaders can tag specific columns within the Catalog as PII, PHI, or Sensitive. Once a column (e.g., customer_email) is tagged, Saddle Data automatically injects and locks hashing or masking transformations into every single flow that uses that data asset.
Engineers no longer have to configure security manually, and they cannot accidentally bypass it. Zero-trust compliance is put on autopilot.
3. The Schema Time Machine
To satisfy compliance audits, Saddle Data tracks all schema drift. When a source database changes, our AI generates human-readable audit logs (e.g., “The ‘email’ column was added to the ‘users’ table on March 15th”), providing an instant, automated history of your data infrastructure.
Enforce data privacy at the infrastructure level. Start securing your data pipelines for free →